
Let’s be honest: AI benchmark fatigue is real
For the last six months, we’ve been squinting at fractional percentage gains on MMLU, trying to convince ourselves that a 0.5% increase is a “breakthrough.” The industry felt stalled in an optimization trap—models were getting faster and cheaper, but not necessarily smarter.
That changed this morning. Google just dropped Gemini 3.1 Pro, and for the first time in a long time, the numbers aren’t just incremental—they’re structural. The headline isn’t the coding speed (though that’s up); it’s the reasoning. Specifically, the performance on ARC-AGI-2 and Humanity’s Last Exam suggests we have finally moved from “predictive text on steroids” to genuine, multi-step problem solving.
The “What”: A Shift from Retrieval to Reasoning
To understand Gemini 3.1 Pro, you have to stop thinking of it as a search engine that talks. Think of it instead as a predictive simulator.
Previous models, including Gemini 3 Pro and GPT-5.2, excelled at pattern matching. If they had seen a similar code snippet in their training data, they could reproduce it perfectly. But give them a novel visual puzzle or a physics problem requiring five leaps of logic? They would hallucinate confident nonsense.
Gemini 3.1 Pro (specifically the “Thinking High” variant) appears to use a new inference-time compute method—likely an evolution of the “Chain of Thought” process we saw in early 2025—allowing it to “ponder” before answering. This is most evident in its ability to handle abstract puzzles where no training data exists.
The Benchmarks: De-Jargonizing the Numbers
The benchmark table provided by Google is dense. Let’s decode the three most critical metrics that prove this model is different.
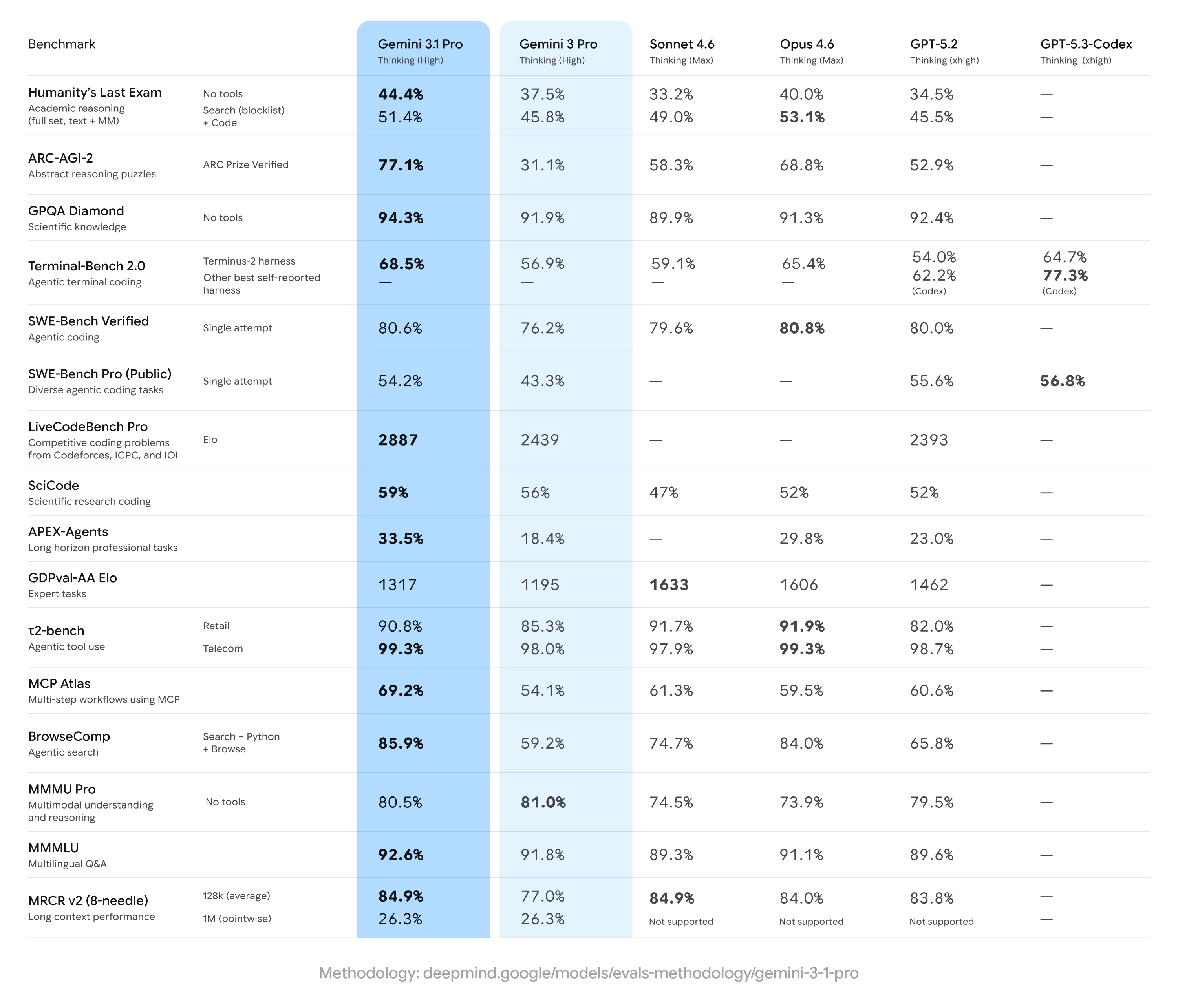
1. ARC-AGI-2 (The “IQ Test”)
- The Score: 77.1% (Gemini 3.1 Pro) vs. 31.1% (Gemini 3 Pro) vs. 52.9% (GPT-5.2).
- What it is: Most benchmarks test knowledge (e.g., “Who was the 12th president?”). ARC-AGI tests fluid intelligence. It gives the AI a grid of colored squares that changes based on a hidden rule (e.g., “all red squares move until they hit a blue wall”) and asks the AI to predict the next grid.
- Why it matters: You cannot “cram” for this test. The massive jump to 77.1% means the model isn’t just retrieving answers; it is formulating and testing hypotheses in real-time. This is the closest proxy we have to human “reasoning.”
2. Humanity’s Last Exam (The “Graduate School” Test)
- The Score: 44.4% (No tools) / 51.4% (Search + Code).
- What it is: A brutal dataset of questions designed to be “Google-proof,” covering niche doctoral-level topics in biology, mathematics, and chemistry.
- The Takeaway: While 44.4% sounds low, context is key. Previous SOTA (State of the Art) models were scoring in the low 30s. Gemini 3.1 Pro is effectively failing less often than anyone else on questions that would stump a tenured professor.
3. LiveCodeBench Pro (The “LeetCode” Test)
- The Score: 2887 Elo.
- What it is: This evaluates models on competitive programming problems from platforms like Codeforces released after the model’s training data cutoff. This prevents “cheating” by memorizing old solutions.
- Real-World Implication: An Elo of 2887 places this model in the “Grandmaster” tier of human programmers. It can solve complex algorithmic problems that require dynamic programming or graph theory, not just boilerplate React components.
The “How”: Implementing Reasoning in Your Workflow
How do you actually leverage this new “reasoning” capability? The key is to force the model to show its work using the new thinking_config parameter (or equivalent in the API).
Here is a Python example of how you might structure a request to solve a logic puzzle, ensuring the model uses its new reasoning budget effectively:
import google.generativeai as genai
# Configure the new 3.1 Pro model
model = genai.GenerativeModel('gemini-3-1-pro')
prompt = """
I have a 5x5 grid.
Row 1 is [0, 1, 0, 1, 0].
The rule for the next row is: Cell[i] becomes 1 if its neighbors (left, right, up) sum to an odd number.
Calculate the state of the grid at Row 5.
"""
# The 'thinking_mode' forces the model to allocate token budget to hidden chain-of-thought
response = model.generate_content(
prompt,
generation_config={
"thinking_mode": "high_reasoning",
"temperature": 0.2
}
)
print(response.text)Pro Tip: For Gemini 3.1 Pro, “Prompt Engineering” is becoming “Context Engineering.” You don’t need to beg the model to “think step-by-step” anymore; you just need to give it the raw data and the constraint. It does the thinking automatically.
The “Vs” Section: Gemini 3.1 Pro vs. The Field
Let’s look at the direct competitors shown in the benchmark report.
Vs. GPT-5.2 (OpenAI)
GPT-5.2 is still a beast, particularly in creative writing and nuance. However, on hard logic (ARC-AGI-2), it trails significantly (52.9% vs Gemini’s 77.1%). If you are building an agent to navigate a complex, undefined software environment, Gemini 3.1 is now the safer bet. If you are writing a novel, GPT-5.2 might still hold the edge.
Vs. Opus 4.6 (Anthropic)
Anthropic’s Opus 4.6 puts up a good fight, specifically in coding (LiveCodeBench). However, Gemini’s integration of “Search + Code” (scoring 51.4% on Humanity’s Last Exam) shows that Google’s ecosystem integration—the ability for the model to “phone a friend” via Google Search or a Python sandbox—is its killer feature.
Vs. GPT-5.3-Codex
Note: Look at the Terminal-Bench 2.0 score. The specialized “GPT-5.3-Codex” model scores 77.3%, beating Gemini’s 68.5%. This is a crucial nuance. If your sole use case is agentic terminal coding (letting an AI control your command line), the specialized Codex model is still superior. Generalist models like Gemini 3.1 are catching up, but specialists still win in narrow lanes.
Future Outlook: The Agentic Horizon
The jump in GPQA Diamond (94.3%) is terrifyingly good. It implies we are approaching a point where the model is effectively omniscient regarding known scientific facts. The next phase isn’t about knowledge; it’s about agency.
With a 68.5% on Terminal-Bench, Gemini 3.1 Pro is competent enough to be given a goal (“Deploy this app to AWS, fix any errors”) and left alone for an hour. It won’t be perfect, but it will get further than any model before it.
Conclusion
Gemini 3.1 Pro is a “boring” release in the best way possible. There are no flashy new voice modes or video generators here. It’s just a massive, undeniable upgrade in raw intelligence. For developers, the message is clear: It’s time to revisit those “impossible” logic problems you shelved six months ago. The hardware inside the machine just got an upgrade.





