Compressing a large language model by 6x without losing any accuracy sounds like a trade-off that doesn’t exist. On March 24, 2026, Google Research published evidence that it does.
The paper introduces TurboQuant, a vector quantization algorithm that targets one of the most expensive problems in running LLMs at scale: the key-value (KV) cache. This is the memory structure that stores frequently accessed data during inference. As context windows grow longer, the KV cache gets heavier, and that drives up hardware costs fast.
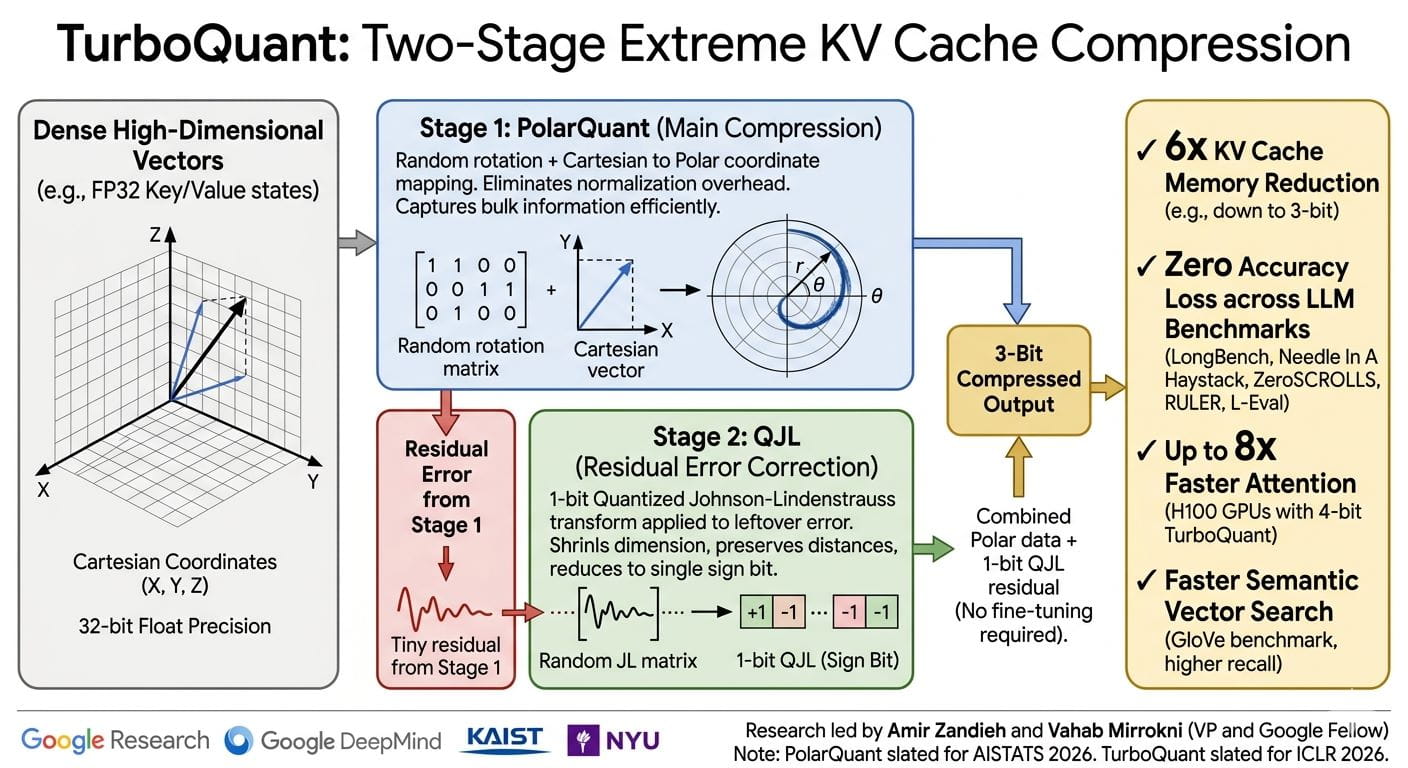
How the three algorithms fit together
TurboQuant is not a single trick. It is a two-stage system built on two sub-algorithms: PolarQuant and QJL.
PolarQuant converts vector data from Cartesian coordinates into polar coordinates. Think of it as replacing “go 3 blocks east, 4 blocks north” with “go 5 blocks at a 37-degree angle.” Because the angle pattern is predictable and tightly concentrated, the model can skip expensive normalization steps entirely. That eliminates the memory overhead that traditional quantization methods always carry.
QJL (Quantized Johnson-Lindenstrauss) handles the residual error left after PolarQuant. It uses the Johnson-Lindenstrauss mathematical transform to shrink high-dimensional data while preserving the distances between points, then reduces each value to a single sign bit (+1 or -1). The overhead: zero. The cost per number: 1 bit.
TurboQuant chains these together. PolarQuant does the heavy compression using most of the available bits. QJL cleans up what’s left with just 1 bit. The combined result is a model that quantizes the KV cache down to 3 bits with no training or fine-tuning required.
The benchmark numbers
The team tested all three algorithms on open-source LLMs, specifically Gemma and Mistral, across five standard benchmarks: LongBench, Needle In A Haystack, ZeroSCROLLS, RULER, and L-Eval.
TurboQuant held full model accuracy across every task, including question answering, code generation, and summarization, while cutting KV cache memory by at least 6x. For “needle in a haystack” tests, which check whether a model can locate one specific fact buried inside a massive document, it scored perfectly.
Speed improved too. Running 4-bit TurboQuant on H100 GPUs, the team recorded up to 8x faster computation of attention logits compared to the 32-bit unquantized baseline. That’s a meaningful reduction in inference costs for anyone running large-scale deployments.
Vector search gets faster too
The KV cache story is only half of it.
Modern search engines match meaning, not just keywords. That requires vector similarity lookups across billions of entries. The TurboQuant team evaluated it against state-of-the-art vector search methods, PQ and RabbiQ, using the GloVe dataset (d=200). TurboQuant hit the best recall ratios without needing large codebooks or dataset-specific tuning.
That matters directly for Google’s search infrastructure. Semantic search at scale means querying massive vector indices constantly. TurboQuant reduces the memory and preprocessing cost of that without giving up accuracy. It’s a practical infrastructure win, not just a research result.
The research was led by Amir Zandieh and Vahab Mirrokni (VP and Google Fellow at Google Research), with contributions from researchers at Google DeepMind, KAIST, and NYU. TurboQuant is slated for presentation at ICLR 2026, and PolarQuant at AISTATS 2026.
If your team runs inference on long-context models and KV cache memory is already a cost line item, read the full papers linked on the Google Research blog before your next infrastructure planning session. The 3-bit, no-fine-tuning angle alone is worth the hour.